最近借 Grafana MCP 做了两次排查。一次是定位内容采集链路里的 Redis 配置问题,另一次是从 Playwright 服务的 zombie 进程告警出发,补齐监控面板和告警规则。
这两次经历给我的感觉是,Grafana MCP 的价值不只是“让大模型能查日志”,而是把日志、指标、代码和部署配置放到同一个排查上下文里。问题不是靠猜出来的,而是沿着 task_id、trace_id、stacktrace 和 Prometheus 指标一步一步收窄出来的。
用 Grafana MCP 排查一次 Redis 配置问题
问题背景
这次问题来自内容采集链路。用户侧提交 Extract 任务后,爬虫服务会抓取目标页面,并把 HTML 上传到 OSS。随后 consumer 消费 spider result 消息,继续做后续的数据解析工作。
问题出现在 consumer 消费完任务之后。当时看到的关键错误日志是:
2026-05-15 16:13:30.864 | ERROR | <consumer-handler> - field discovery error for detail=<detail_id> task=<task_id>: illegal address: 10.x.x.x:<port>传统排查思路
10.x.x.x 是私网 IP 地址,所以第一反应通常是怀疑外部通信出了问题,比如 OCR 接口、OSS 下载、模型接口、MySQL、Redis、Consul 等。排查重点会落在基础设施层,因为从经验看,这类报错很像连接被拒绝。
基于 Grafana MCP 的思路
基于 Grafana,我之前已经建立了一套比较完整的日志体系,可以通过某一段日志里的 trace_id 还原出整个业务流程。也就是说,只要沿着日志往前后查,就有机会直接锁定问题范围。
所以这次我没有先按传统方式逐个服务排查,而是尝试让 LLM 根据这条日志自己找问题。核心工具就是 Grafana MCP。配置好 grafana-mcp 和相关的 auth token 后,大模型就可以直接查询 Grafana 里的数据。
这里不需要太多 prompt 技巧,我的唤起方式如下:
下面是 LLM 自己展开问题排查的过程。
LLM 处理过程
1. 先用 task_id 串起业务链路
通过 Grafana MCP 查询 Loki,先用 task_id=<task_id> 做全局检索,确认同一任务在多个服务中的日志顺序。
查到的关键信息包括:
backend-service在 16:13:21 已经把 1 个 URL 推入 spider queue。spider-service在 16:13:26 抓取成功,并推送 spider result。- spider result 中包含
detail_id=3、status=success、目标 URL 和html_oss_url。 consumer-service在 16:13:26.876 开始消费该消息。consumer-service在 16:13:30.864 抛出illegal address。- 随后
check_and_finalize记录status=5, total_rows=0。
这一步排除了“爬虫没抓到页面”和“spider result 没有投递”两个方向。爬虫侧已经成功,问题发生在 consumer 后处理阶段。
2. 对 consumer 日志按 trace_id 和 detail_id 缩小范围
继续用 Grafana MCP 按 trace_id=<trace_id> 和 detail=<detail_id> 查询 consumer-service。
结果显示,这条 consumer 消息的生命周期很短:
- 消费开始:16:13:26.876
- 报错:16:13:30.864
- 消费结束:16:13:31.157
- 总耗时:4281.32 ms
当时这条日志没有完整堆栈,只能看到 _handle_extract_field_discovery 的外层错误,于是继续查当天同类错误。
3. 查询同类 field discovery error,找到完整堆栈
用 Grafana MCP 查询当天 consumer-service 中的 field discovery error 和 illegal address,发现 16:35:39 又出现了一条同类错误,并且这次带了完整 stacktrace。
完整堆栈显示,真正失败点不是 OSS、HTML 转换或 LLM,而是在字段发现一开始获取 Redis 分布式锁:
lock_acquired = await RedisHubAsync.setnx("REDIS_LOCK_ALIAS", lock_key, "1")调用链继续指向:
<redis-client-module>:<line> - return await r.setnx(key, value)
redis.asyncio.connection.Connection(host=<redis-host>, port=<port>, db=<db>)
redis.exceptions.ResponseError: illegal address: <client-private-ip>:<port>这一步是关键证据。illegal address 是 Redis 服务端在连接认证或命令执行阶段返回的 ResponseError,不是 Python 代码主动抛出的业务异常。
4. 回到代码确认失败位置
结合代码看,_handle_extract_field_discovery 在真正下载 OSS HTML、转换 Markdown、调用字段推荐前,会先通过 Redis 锁保护同一个 task 的字段发现流程:
lock_key = f"extract:field_config:{task_id}"
lock_acquired = await RedisHubAsync.setnx("REDIS_LOCK_ALIAS", lock_key, "1")所以如果锁服务使用的 Redis 连接不可用,field discovery 会在最前置的锁阶段失败。后面的 OSS、Markdown、LLM 流程根本还没开始。
处理结果
最终判断:问题根因是 Redis 锁配置错误。consumer-service 访问错误的 Redis 实例时被服务端拒绝,错误表现为:
redis.exceptions.ResponseError: illegal address: <client-private-ip>:<port>后来经过确认,这个判断是正确的。处理方式是把 Redis 锁使用的配置别名切换到 consumer 专用实例,consumer 不再访问错误的 Redis 配置,问题得到解决。
问题复盘
根据 LLM 排查出来的结论,我最终找到了问题原因:做配置切换时,Redis 锁相关的配置没有一起切换,导致代码加锁时遭遇 Redis 报错。
这是一个比较低级的错误。但因为日志归属于 field discovery 的全局异常捕获,如果纯人工排查,可能真不太容易第一时间发现。
经验总结
这次排查里,Grafana MCP 的价值主要体现在三点:
- 完整的日志体系很重要,比如用同一个
task_id、trace_id横向串起 backend、spider、consumer 的完整业务链路。 - 可以从单条无堆栈错误扩展到同类错误检索,找到带完整 stacktrace 的样本。
- Grafana MCP 能把代码和日志结合起来,在结构性的报错中快速定位原因和解决方案。
使用 Grafana 快速迭代监控面板
上面的案例主要体现的是 Grafana MCP 在日志排障上的价值。实际上,它还有一个很实用的场景:当一次事故暴露出现有监控盲区时,可以让 LLM 结合 Grafana 当前数据、项目代码和监控仓库,快速补齐新的指标、告警和 dashboard。
这次例子来自 playwright-service 的一次 zombie 进程告警。
问题背景
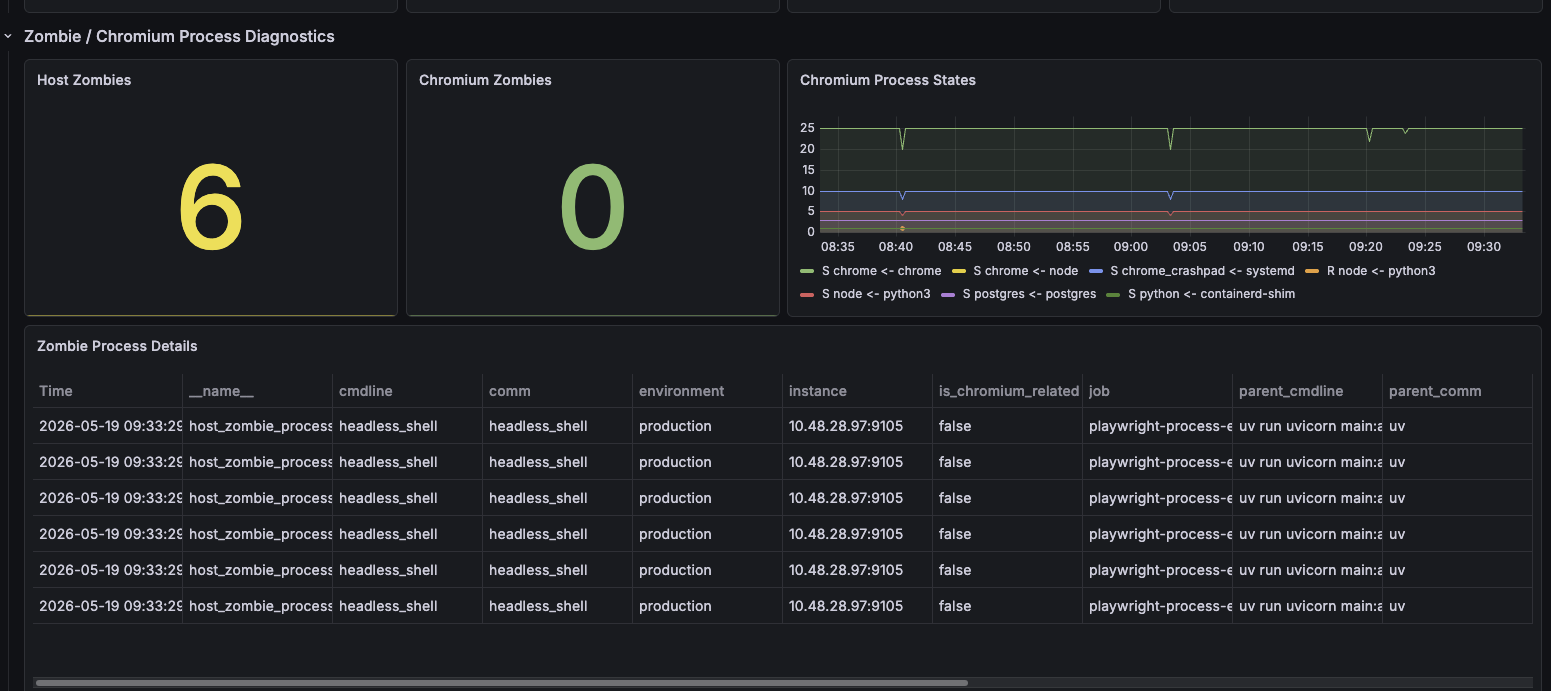
5 月 16 日 01:27,系统出现了 procs_zombie > 20 的告警,实时值是 24。后来通过重启 playwright-service 的 Docker 容器恢复,因此初步怀疑问题来自这个服务。
这个服务的日志可以在 Loki 中通过下面的 selector 查询:
{service_name="playwright-service"}如果只看告警本身,只能知道 zombie 数量超阈值,但不知道 zombie 是谁创建的、父进程是谁、是否真的和 Chromium/Playwright 有关。这类问题很适合借助 Grafana MCP 做一次“从事故到监控补洞”的闭环。
1. 先用 Loki 还原异常时间线
排查时先把告警时间换算清楚:告警时间是北京时间 2026-05-16 01:27,而日志正文中的时间是 UTC,所以 Loki 里看到的 2026-05-15 17:23 实际对应北京时间 2026-05-16 01:23。
通过 Grafana MCP 查询告警前后的 playwright-service 日志,发现告警前几分钟已经出现了明显的浏览器驱动异常:
Connection closed while reading from the driverBrowser stale detected, reinitializing chromeWriteUnixTransport closed=True ... the handler is closedBrowser.close: unable to perform operation ... the handler is closed- 多条
Global hook timeout after 5.0s
这些日志说明,当时并不是普通业务报错,而是 Patchright/Playwright 与 Chromium 之间的 driver 连接已经异常断开。
2. 再用 Prometheus 判断是不是应用层资源泄漏
继续通过 Grafana MCP 查询 Prometheus 指标,包括:
browser_active_pages
browser_active_contexts
browser_instances
processing_requests
browser_reinitializations_total结果显示,browser_active_pages 和 browser_active_contexts 没有持续增长,最高只是短时间到 6 左右;browser_instances 也维持在正常数量。这说明问题不太像应用层 Page/Context 长期没有释放,更像是底层 Chromium 子进程异常退出后,没有被容器内的 PID 1 正常回收。
结合代码和部署方式继续看,playwright-service 的容器 entrypoint 是:
/bin/bash scripts/start_service.sh脚本最后启动 gunicorn 时没有使用 exec,容器里也没有 tini 或 dumb-init 这样的 init/subreaper。对于 Playwright/Chromium 这类会拉起多个子进程的服务,这就是一个很典型的 zombie 进程观测盲区:现有告警能告诉我们“有 zombie”,但不能告诉我们“谁变成了 zombie”和“父进程是谁”。
3. 把排查结论转成监控需求
这一步是 Grafana MCP 很有价值的地方。它不只是帮忙查日志,也可以把刚刚的排查结论翻译成监控面板应该补什么。
这次新增的监控目标很明确:
- 能看到宿主机当前 zombie 进程总数。
- 能区分其中有多少 zombie 和 Chromium、Patchright、Playwright 有关。
- zombie 出现时,能够直接看到
pid、ppid、comm、cmdline、parent_comm、parent_cmdline。 - dashboard 上能看到 Chromium 相关进程按 state 的分布,而不是只看到一个总数。
最后落地成一个轻量的 host PID /proc exporter,由 Prometheus 抓取它暴露的指标:
host_zombie_processes
playwright_chromium_zombie_processes
playwright_chromium_processes{state,comm,parent_comm}
host_zombie_process_info{pid,ppid,comm,cmdline,parent_comm,parent_cmdline,is_chromium_related}这里需要注意权限边界:这个 exporter 使用 pid: host 并只读挂载宿主机 /proc,可以看到宿主机进程列表和命令行参数。因此它不是一个无感知的小改动,应该明确知道自己在增加什么能力,以及这些指标会暴露什么信息。
4. 快速更新 dashboard 和告警规则
完成指标设计后,就可以让 LLM 直接修改 devops 里的监控配置:
- 在
docker-compose.yml中新增playwright-process-exporter。 - 在
prometheus.yml中新增 scrape job。 - 在
alerts.yml中新增PlaywrightChromiumZombieProcesses和HostZombieProcessesHigh告警。 - 在
playwright-servicedashboard 中新增一组面板:Host ZombiesChromium ZombiesChromium Process StatesZombie Process Details
这样下一次再出现 procs_zombie > 20 时,就不用停留在“怀疑是 playwright-service”这个层面,而是可以直接在 dashboard 里看到 zombie 的 pid/ppid 和父进程命令行,判断它到底是不是 Chromium 相关进程,以及是否由 gunicorn/容器 init 回收链路引起。
经验总结
这个过程里,Grafana MCP 的价值不只是查一次日志,而是把监控迭代也纳入了同一个工作流:
- 先通过 Loki 和 Prometheus 还原事故事实,避免凭经验拍脑袋加指标。
- 再结合代码和部署配置判断真正缺失的观测维度。
- 最后把新的观测维度落实到 exporter、Prometheus scrape、告警规则和 dashboard 面板中。
也就是说,LLM 不只是一个排障助手,还可以作为监控体系的迭代助手。一次事故结束后,最有价值的产出不只是“这次怎么修”,还包括“下次出现同类问题时,dashboard 能不能直接给出答案”。
结果案例: