
本篇主要的内容是如何对 Docker 镜像进行优化.
优化总共分为以下几步:
- 基于项目优化
- 缩减依赖包
- 基于Docker优化
- 目录结构优化
- 构建文件优化
- 使用 dive 进行镜像分析
以及部分 Multi-stage build 的内容.
最初的镜像大小为2.3G, 造成这个离谱的镜像大小的原因很多, 接下来将一层一层地抽丝剥茧.
基于项目优化
缩减依赖包大小
项目的一个遗留问题就是, 在项目开始的时候使用了之前项目的 Python 虚拟环境. 所以在导出 requirements.txt 的时候混进了一些不必要的依赖内容.
笔者使用的是 Poetry 进行项目包管理, 它会自动地生成一份 poetry.lock 文件, 能够较快的在新的环境中实现依赖的安装. 同时, 它也会剪去不必要的依赖.
另外一个缩减依赖包的方法, 是查找较大的依赖包, 并且优化掉一些可以使用本地代码替代的依赖内容.
使用如下的命令列出当前项目中使用到的依赖的大小.
pip list | tail -n +3 | awk '{print $1}' | xargs pip show | grep -E 'Location:|Name:' | cut -d ' ' -f 2 | paste -d ' ' - - | awk '{print $2 "/" tolower($1)}' | xargs du -sh 2> /dev/null | sort -hr笔者在这一步找到了 pandas , 之前为了省事使用了 DataFrame 的数据聚合功能, 但是为此引入 100M+ 的 Pandas + Numpy 依赖组合, 显然是不值得的.
使用综上的两种缩减依赖的思路之后, 将镜像的大小压缩到了 1.8G 左右.
基于Docker的优化
目录结构优化
dockerignore
Docker 在构建镜像时, 会以指定的文件夹(context)为基础, 然后执行 Dockerfile . 所以对于前后端分离的项目, 只需要将 context 指定到对应的 前端\后端 项目目录即可, 不需要直接覆盖整个项目目录.
此外, 正如 git 支持通过 gitignore 来忽略掉不需要的文件, Docker 也可以使用 dockerignore 来剪掉非必要的文件.
这里笔者把剪掉的一些文件列出来, 以供参考.
- .git
- .idea
- pytorch模型文件
构建文件优化
基础镜像
以 Python 为例, 官方给出了很多的镜像版本, 其中, python:latest 这类的镜像体积最大, 其中包含了很多未被过滤的不必要的包, 一般用于编译等功用. 而 python:alpine 则是基于 alpine 系统的, 拥有目前而言最精简的体积.
以 linux/amd64 架构为例, 前者的镜像大小是后者的 19 倍.
| python | python-alpine |
|---|---|
| 334.72 MB | 17.74 MB |
需要注意的是, alpine的精简是建立在移除很多编译所需的包的基础上的, 所以在安装包的时候, 需要使用
apk加入一些必要的系统级依赖.!!! WARNING !!!
使用 alpine 需要对各个依赖有较为清晰的认识, 不然很可能会陷入不断安装依赖的泥潭中. 如果没有, 或者想要避免这部分的麻烦, 可以使用 slim 版本或者原版.
此外, 对于 flask 项目来说, 一般会引入 gunicorn 提高运行效率, 这里笔者一开始图省事, 选用的是 meinheld-gunicorn 这个镜像, 但是深入研究(见于后文的 镜像分析 )之后发现, 这个镜像本质上是基于对 python:alpine 的一层封装, 所以最终还是继续使用 python:alpine 作为基础镜像.
删除cache
在poetry \ pip \ yarn 这类包管理系统安装依赖包的时候, 会使用 缓存 来减少之后重复安装所带来的损耗, 当然, 在使用 Docker 打包镜像的时候, 完全不需要考虑重复安装的问题, 所以完全可以将这些缓存文件删除, 或者使用类似 --no-cache 这类的参数约束包管理器跳过缓存.
使用dive进行镜像分析
到这一步, 我们根据表层信息能做的优化基本上到了一个瓶颈, 如果需要更深入的优化, 则需要将镜像包解开, 看看镜像内部的”风景”.
这里我们会用到 dive 这个开源工具.
使用 dive <your-image-tag> 即可以进入镜像内部.
如下图所示, 是我们的最初的镜像.
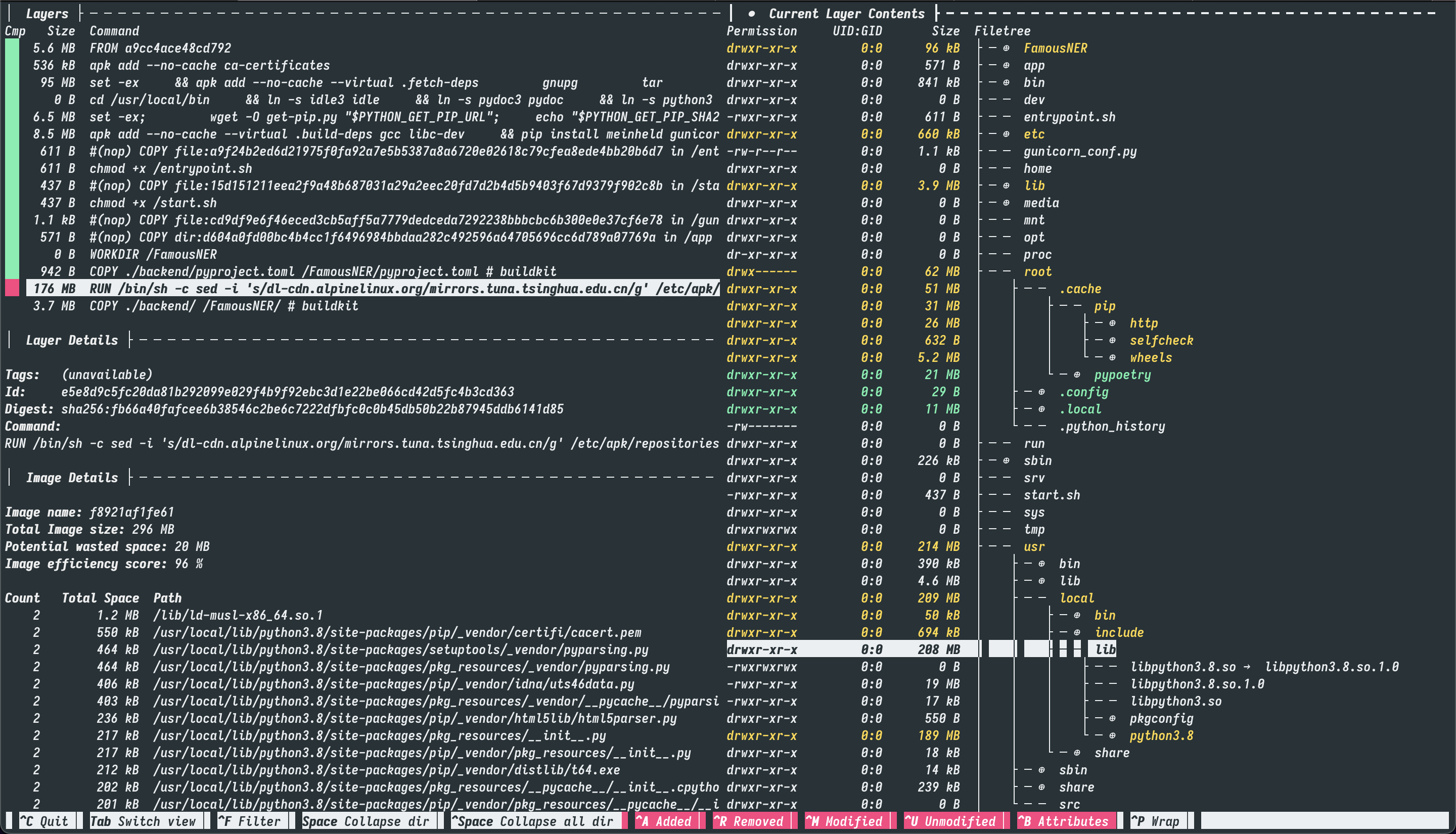
看懂这个图, 首先需要理解 docker 中的一个概念, 即 layer(层) . 详细的可以阅读相关的文档.
Each layer is only a set of differences from the layer before it. Note that both adding, and removing files will result in a new layer.
一言以蔽之, layer是一个记录了与上一层layer差异的集合. 知道了这一点之后, 再看上面的dive分析图, 左侧可以选择不同的layer, 右侧则根据 git 的标色习惯列出了与上一层的变更内容.
所以我们在编写Dockerfile的时候, 需要尽可能地减少layer的数量, 因为即使你在下一层中删除了一些文件, 但是这些文件依然会存在于上一层镜像中, 甚至你会因为你的删除操作而导致镜像体积更大.
至此, 我们可以着手进行镜像的分析了. 为了更直观地解释, 这里贴出笔者的 Dockerfile.
# pull official base image
FROM tiangolo/meinheld-gunicorn:python3.8
WORKDIR /FamousNER
USER root
...pass
# install dependencies
COPY ./backend/pyproject.toml ./backend/poetry.lock /FamousNER/
RUN apk add --no-cache --virtual .build-deps gcc libc-dev libffi-dev python3-dev musl-dev make build-base \
&& pip install --upgrade pip setuptools wheel -i https://pypi.douban.com/simple \
&& pip install "poetry==$POETRY_VERSION" -i https://pypi.douban.com/simple \
&& poetry config virtualenvs.create false \
&& poetry install --no-interaction --no-ansi --no-dev \
&& apk del .build-deps gcc libc-dev libffi-dev musl-dev make build-base
# copy project
COPY ./backend/ /FamousNER/
首先我们可以看到, 有一个 176M 的 layer, 占据了这整个image绝大的体积.
我们使用dive进入到这一层中, 可以很明显地看到, 在 /root 文件夹下有一些残留的缓存文件, 在 docker 构建中, 所有的缓存都是可以清除的, 所以我们可以在这一层的Dockerfile中加入 rm -rf /root/.cache/ 用来手动删除依赖安装过程中产生的缓存信息.
然后一个迷惑的地方是, Dockerfile 中明明只执行了一次 RUN, 但是在镜像分析中却有着很多层的 RUN 命令.
这个是因为 FROM tiangolo/meinheld-gunicorn:python3.8 这一句, 引用了第三方的镜像, 而第三方的镜像构建命令也被dive分析展示出来了.
所以为了缩减layer, 我们将 tiangolo/meinheld-gunicorn 这个镜像中的一部分对我们有用的构建命令摘出来, 回归 alpine 作为基础镜像.
综上, 我们能够得到如下所示的镜像构建文件.
# pull official base image
FROM python:3.8-alpine
WORKDIR /FamousNER
USER root
...pass
# install dependencies
COPY ./backend/pyproject.toml ./backend/poetry.lock /FamousNER/
RUN apk add --no-cache --virtual .build-deps gcc libc-dev libffi-dev python3-dev musl-dev make build-base \
&& pip install --upgrade pip setuptools wheel -i https://pypi.douban.com/simple \
&& pip install "poetry==$POETRY_VERSION" -i https://pypi.douban.com/simple \
&& poetry config virtualenvs.create false \
&& poetry install --no-interaction --no-ansi --no-dev \
&& poetry add meinheld==1.0.2 \
&& poetry add gunicorn==20.1.0 \
&& yes | poetry cache clear . --all \
&& apk del .build-deps gcc libc-dev libffi-dev musl-dev make build-base \
&& rm -rf /root/.cache/
# copy project
COPY ./backend/ /FamousNER/
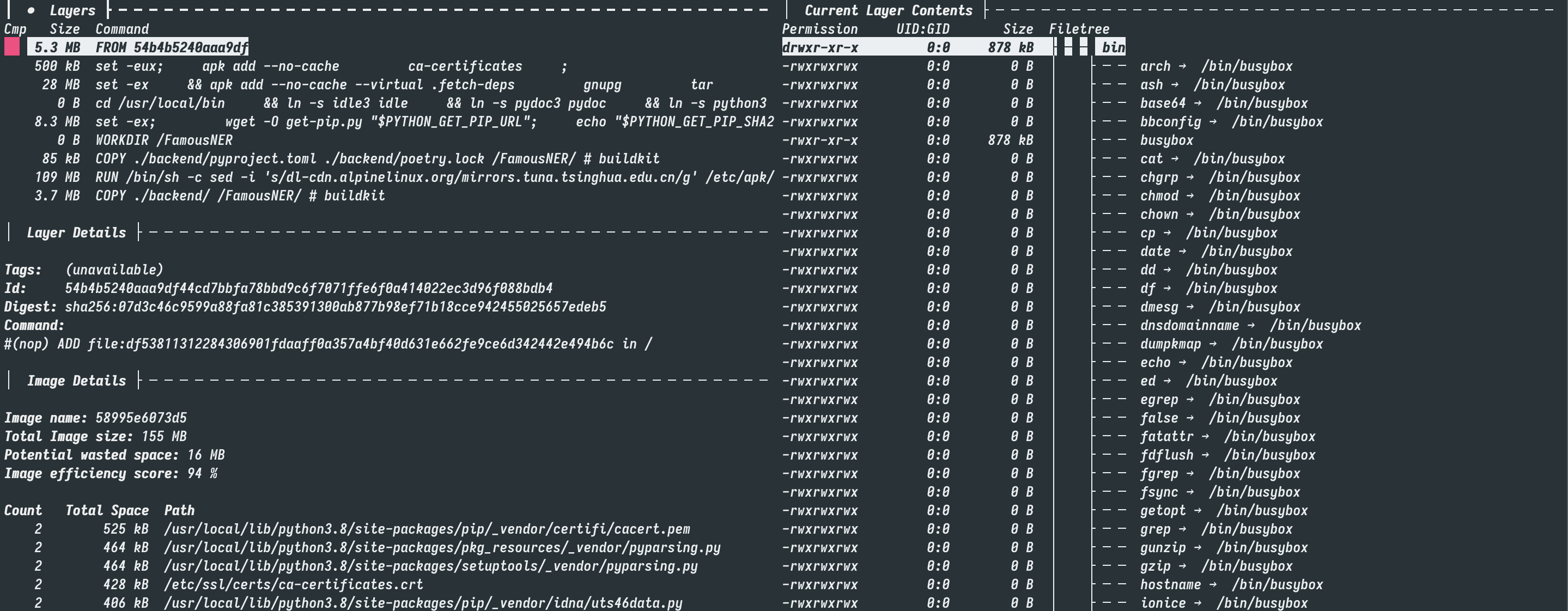
而通过这个构建文件, 我们最终将镜像的体积压缩到了 155.7MB . 而之前的镜像几乎是它的15倍.
Multi-stage build
Multi-stage build 是 docker 官方文档中推荐的一种构建更轻量的镜像的方式. 可见于 官方文档 .
官方使用的是 golang 作为范例, 而事实上 Multi-stage 确实对于这种编译型语言有着很强的优化作用.
编译型语言一旦完成项目的编译, 语言本身就不重要了, 即使系统里没有安装 golang , 但是只要使用编译好的可执行文件, 就可以启动程序. 也就是, 这是编译和执行分离的一种构建方式.
在这里我同样也尝试了这样的构建方法.
# `python-base` sets up all our shared environment variables
FROM python:3.8-alpine as python-base
# python
ENV PYTHONUNBUFFERED=1 \
# prevents python creating .pyc files
PYTHONDONTWRITEBYTECODE=1 \
\
POETRY_VERSION=1.1.4 \
# make poetry install to this location
POETRY_HOME="/opt/poetry" \
POETRY_VIRTUALENVS_IN_PROJECT=true \
POETRY_NO_INTERACTION=1 \
\
# paths
# this is where our requirements + virtual environment will live
PYSETUP_PATH="/opt/pysetup" \
VENV_PATH="/opt/pysetup/.venv"
# prepend poetry and venv to path
ENV PATH="$POETRY_HOME/bin:$VENV_PATH/bin:$PATH"
# `builder-base` stage is used to build deps + create our virtual environment
FROM python-base as builder-base
RUN sed -i 's/dl-cdn.alpinelinux.org/mirrors.tuna.tsinghua.edu.cn/g' /etc/apk/repositories \
&& apk add --no-cache --virtual .build-deps gcc libc-dev libffi-dev python3-dev musl-dev make build-base \
&& pip install --upgrade pip setuptools wheel -i https://pypi.douban.com/simple \
&& pip install "poetry==$POETRY_VERSION" -i https://pypi.douban.com/simple
# && poetry config virtualenvs.create false
# copy project requirement files here to ensure they will be cached.
WORKDIR $PYSETUP_PATH
COPY ./backend/poetry.lock ./backend/pyproject.toml ./
# install runtime deps - uses $POETRY_VIRTUALENVS_IN_PROJECT internally
RUN poetry install --no-dev \
&& poetry add meinheld==1.0.2 \
&& poetry add gunicorn==20.1.0
FROM python-base as production
COPY --from=builder-base $PYSETUP_PATH $PYSETUP_PATH
COPY ./backend/ /FamousNER/
WORKDIR /FamousNER可以看到, 本质上是将安装依赖等工作放到了另一个镜像里, 将依赖编译\安装之后, 直接将成果拷贝到主镜像文件中. 这样就不需要去考虑安装依赖过程中产生的各种缓存问题了.
对于 python 这类解释性语言来说, 即使在我们使用了之前的优化策略之后, multi-build 带来的提升依旧是巨大的. 如下图所示, 通过这种范式构建出来的镜像, 体积只有 105MB , 比之前的多重优化之后的镜像, 又缩减了近 1/3 .
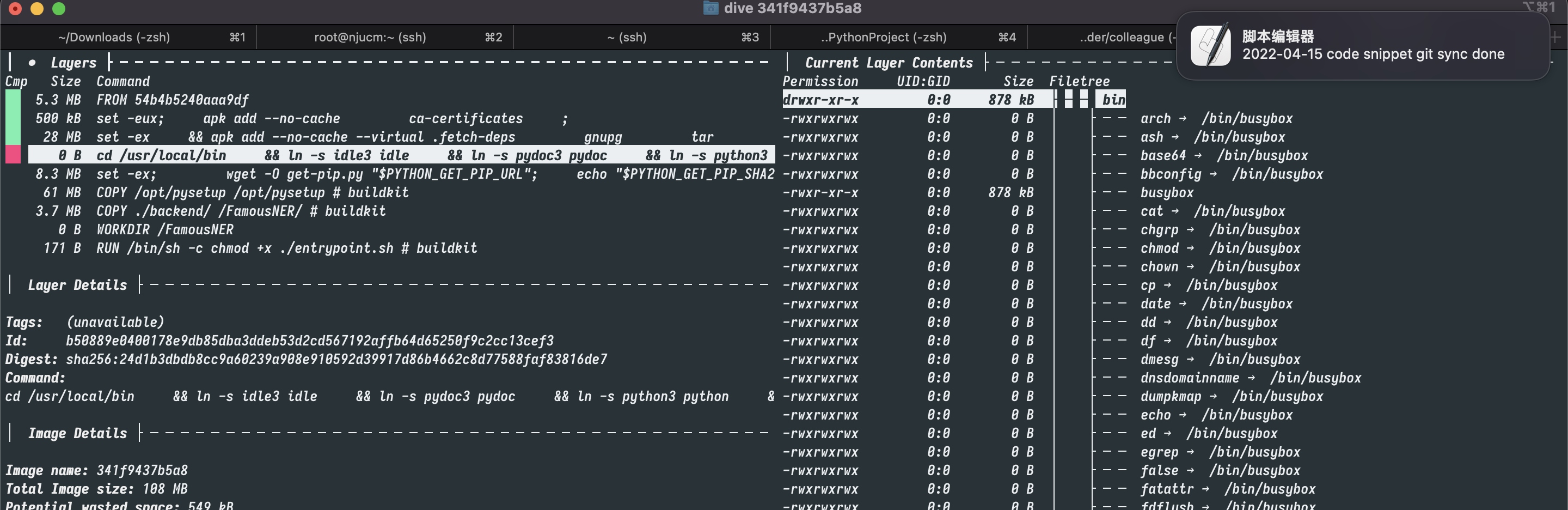
不过 multi-build 并非银弹, 本项目由于只是用了 python 的依赖内容, 所以只需要将前面几步得到的依赖文件(也就是虚拟环境)拷贝一下就行, 而面对复杂的项目, 存在很多的系统级的依赖, 哪些文件是需要拷贝的, 哪些是需要丢弃的, 可能会是一个较大的挑战.

