引入
根据笔者以往的爬虫经验,大部分的爬虫是在静态网页上完成的,爬虫所要做的只不过是提交请求,然后分析返回的页面即可。当然,api 本质上也可以作为静态页面来处理。这意味着只要掌握 requests 就可以完成 60%-80%的爬虫任务。
这是一个很惊人的占比,这里解释一下,静态页面可能听起来很 low,但是有着以加载速度更快、易于维护为核心的一系列优势,尤其是引入了 ajax 之后,实现了动态加载,通过更加频繁的前后端交互,使得用户的使用更加丝滑流畅。
但是总有一些网站是静态爬虫无法应付的。它们就是与 js 耦合度较高的,需要 js 进行渲染的页面,与上文所述的情况(前端只接收数据,而不用对数据进行计算层面的处理)不同,这类网站将部分的计算工作交托给前端,牺牲部分的用户体验来实现缓解服务器压力等一系列目的。
这就是剩下的 20%了。如何处理这些刺头呢?这就引出了本文的主角–splash。
关于 splash
Splash 是一个针对 js 的渲染服务。它内置了一个浏览器和 http 接口。基于 Python3 和 Twisted 引擎。所以可以异步处理任务。
关于 splash,国内目前的大部分博客教程都停留于对官方文档的翻译,所以还是推荐有能力的直接看文档,毕竟还有一个时效性。
安装 && 运行
docker pull scrapinghub/splash
docker run -p 8050:8050 -p 5023:5023 scrapinghub/splash一个简单的 splash 应用
抓取今日头条,对比渲染和没有渲染的效果
import requests
from lxml import etree
url = 'http://localhost:8050/render.html?url=https://www.toutiao.com&timeout=30&wait=0.5'
# url = 'https://www.toutiao.com'
response = requests.get(url)
tree = etree.HTML(response.text)
article_titles = tree.xpath('//div[@class="title-box"]/a/text()')
print(article_titles)[‘总书记来过我们家,脱贫了还要好好干’, ‘北京2020年初雪已进城!您那儿下起来了吗?’, ‘论萌娃写作业时,求生欲有多强:爸爸我给你鼓掌’, ‘秦平:弘扬黄河文化,凝聚追梦中国精神力量’, ‘苏莱曼尼之死,全世界到底在怕什么?’, ‘观景平台,“零距离”看飞机’, ‘浙江一企业保险箱被撬,120万现金仅被偷走27万!小偷:当时想起一句“名言”……’, ‘划重点2020双闰年 网友:鼠年要多上一个月的班’, ‘若美伊全面开战,中国将再获20年发展机遇期?’]
如果没有渲染,那么得到的结果就是一个空的数组,只有进行了 js 渲染才能得到我们想要的结果。
开始玩耍吧~
起因
前几天看电视剧时一时兴起(好吧,这就是老年人),想分析一下近年来的中国电视剧发展趋势,加上正好某鲨想要学爬虫,于是就重操旧业,开启了一个新坑。
首先,从哪里获得数据呢?
将目标锁定到了豆瓣(好吧,从某种层面上来说我也算是豆瓣的老用户了,经常因为使用爬虫被封号的那种(笑))。
具体点说,是豆瓣排行榜,在进行了网页分析之后,发现所有的数据都是通过 api 回传的,这感情好,直接上 requests 莽一波就完事了。
问题出现
爬完之后发现,豆瓣排行榜只放出了前 500 条数据,500 条能干啥哦???
尝试解决
重新寻找,发现豆瓣的搜索功能可以一试。于是搜索关键词“1990+电视剧”,果然,1990 年的电视剧就都出来了。但是,分析了半天网页,没有发现什么 api?于是开始进行第二轮的地毯式分析,果然,在主页面的 html 文件里发现了一条又臭又长的数据“window.__DATA__”,里面存放了一大堆的诡异的字符串,这。。。。!?忽然想起来前几天看的密码学,不就是这个鲨雕样子吗,那么很大概率就是豆瓣对自己的数据进行了加密!

开始排查
使用 url 过滤,配合二分法截断 url,再用 js 断点调试,最后在 bundle.js 文件里发现了解密过程。
这时有两条路可以选择。
- 解密
- 不解密
于是又刷新了一下网页,“window.__DATA__”存放的数据变了。。。变了。。。好吧,竟然还采用了动态密钥,我解密个锤子哦?果断选择第二条路。
解决方案
既然你用 js 渲染解密,那我就等你渲染完了再爬呗~
我是示例
数据获取
import requests
from urllib.parse import quote
import json
import time
import pandas as pd
# 初始化Dataframe
df = pd.DataFrame()
# 记录序号
index = 0
def get_soup(url_raw):
'''
@description: 获取指定url的数据并将其解析为soup
@param {type}
url_raw {string}
@return: BeautifulSoup的解析结果
'''
try:
## lua脚本
lua = '''
function main(splash, args)
assert(splash:go("'''+url_raw+'''"))
return {
html = splash:html(),
png = splash:png(),
har = splash:har(),
}
end
'''
url = 'http://localhost:8050/execute?lua_source=' + quote(lua)
response = requests.get(url)
js = json.loads(response.text)
soup = BeautifulSoup(js['html'])
return soup
except Exception as e:
print(e)
time.sleep(10)
def html_parser(soup,year):
'''
@description: 解析网页,提取结果
@param {type}
soup {BeautifulSoup} 解析完成的soup
year {int} 第几年
@return:
'''
tv_detail = [foo for foo in soup.find_all(class_='item-root') if re.search('.*'+str(year)+'.*',foo.find(class_='title-text').text)]
for foo in tv_detail:
index+=1
if foo.find(class_='rating_nums'):
df.loc[index,'year'] = year
df.loc[index,'rating_nums'] = foo.find(class_='rating_nums').text
df.loc[index,'rating_people'] = re.search('\D*(\d*)\D*',foo.find(class_='pl').text).group(1)
df.loc[index,'title'] = foo.find(class_='title-text').text
split_res = foo.find(class_='meta abstract').text.replace(' ','').split('/')
df.loc[index,'country'] = split_res[0]
df.loc[index,'tv_type'] = ','.join([foo for foo in split_res[1:] if len(foo)<=2])
for year in range(1991,2019):
# url后缀参数
start_num = 0
while(1):
url_raw_1 = "https://search.douban.com/movie/subject_search?search_text={}+电视剧&start={}".format(year,start_num*15)
soup = get_soup(url_raw_1)
html_parser(soup,year)
# 判断是否存在后续页(若无,则该年结束,继续下一年的爬取)
if not soup.find(class_='next activate'):
start_num+=1
else:
# 这一过程耗时较长,为了防止意外导致数据丢失,所以每一年的爬取完成之后,保存结果
df.to_csv('tv_data_1990_2018.csv')
break
df.info()<class 'pandas.core.frame.DataFrame'>
Int64Index: 7426 entries, 3 to 8817
Data columns (total 6 columns):
year 7426 non-null float64
rating_nums 7426 non-null object
rating_people 7426 non-null object
title 7426 non-null object
country 7426 non-null object
tv_type 7426 non-null object
dtypes: float64(1), object(5)
memory usage: 726.1+ KB嗯,1990 年-2018 年一共获取了 7426 条数据,似乎没啥问题。
开始进行数据清洗吧。
数据清洗
- 由于之前的序号不是严格顺序的(因为各种因素出现序号断层),我们将数据重新排序,并且指定新的序号(强迫症了)。
- 在上面的 info 表中,可以发现,rating_nums 和 rating_people 两项,我希望它是 float 类型的。
- 部分国家的电视剧数量太少,由于现在主要的分析目标是中国电视剧发展趋势,所以将 30 年来电视剧统计量小于 100 的剔除掉
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from collections import Counter
import redfnew = df.sort_index().reset_index().drop(columns=['index'])
dfnew['rating_nums'] = dfnew['rating_nums'].astype('float')
dfnew['rating_people'] = dfnew['rating_people'].astype('int')
dfnew['year'] = dfnew['year'].astype('int')
countries = [k for k,v in Counter(df.country).items() if v > 300]
df_final = dfnew.drop(index=[index for index in dfnew.index if dfnew.loc[index,'country'] not in countries])
df_final = df_final.sort_index().reset_index().drop(columns=['index'])
df_final.head()<div>
<style scoped>
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>year</th>
<th>rating_nums</th>
<th>rating_people</th>
<th>title</th>
<th>country</th>
<th>tv_type</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>1991</td>
<td>9.4</td>
<td>101919</td>
<td>东京爱情故事 東京ラブストーリー (1991)</td>
<td>日本</td>
<td>爱情</td>
</tr>
<tr>
<th>1</th>
<td>1991</td>
<td>9.6</td>
<td>4490</td>
<td>成长的烦恼 第七季 Growing Pains Season 7 (1991)</td>
<td>美国</td>
<td>喜剧,家庭</td>
</tr>
<tr>
<th>2</th>
<td>1991</td>
<td>9.2</td>
<td>1509</td>
<td>宋飞正传 第三季 Seinfeld Season 3 (1991)</td>
<td>美国</td>
<td>喜剧</td>
</tr>
<tr>
<th>3</th>
<td>1991</td>
<td>7.4</td>
<td>4598</td>
<td>外来妹 (1991)</td>
<td>中国大陆</td>
<td>剧情,爱情</td>
</tr>
<tr>
<th>4</th>
<td>1991</td>
<td>8.9</td>
<td>2140</td>
<td>宋飞正传 第二季 Seinfeld Season 2 (1991)</td>
<td>美国</td>
<td>喜剧</td>
</tr>
</tbody>
</table>
</div>开始分析
df_year_rate = df_final[['rating_nums','year','country']].groupby(['year','country'],as_index=False).aggregate(np.average)
df_year_rate.head()<div>
<style scoped>
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>year</th>
<th>country</th>
<th>rating_nums</th>
</tr>
</thead>
<tbody>
<tr>
<th>0</th>
<td>1990</td>
<td>美国</td>
<td>9.600000</td>
</tr>
<tr>
<th>1</th>
<td>1991</td>
<td>中国大陆</td>
<td>6.966667</td>
</tr>
<tr>
<th>2</th>
<td>1991</td>
<td>中国香港</td>
<td>7.388889</td>
</tr>
<tr>
<th>3</th>
<td>1991</td>
<td>日本</td>
<td>8.400000</td>
</tr>
<tr>
<th>4</th>
<td>1991</td>
<td>美国</td>
<td>8.771429</td>
</tr>
</tbody>
</table>
</div>plt.figure(figsize=(50,20))
sns.lineplot(x=df_year_rate.year,y=df_year_rate.rating_nums,hue=df_year_rate.country)
plt.xticks(rotation=90)(array([1985., 1990., 1995., 2000., 2005., 2010., 2015., 2020.]),
<a list of 8 Text xticklabel objects>)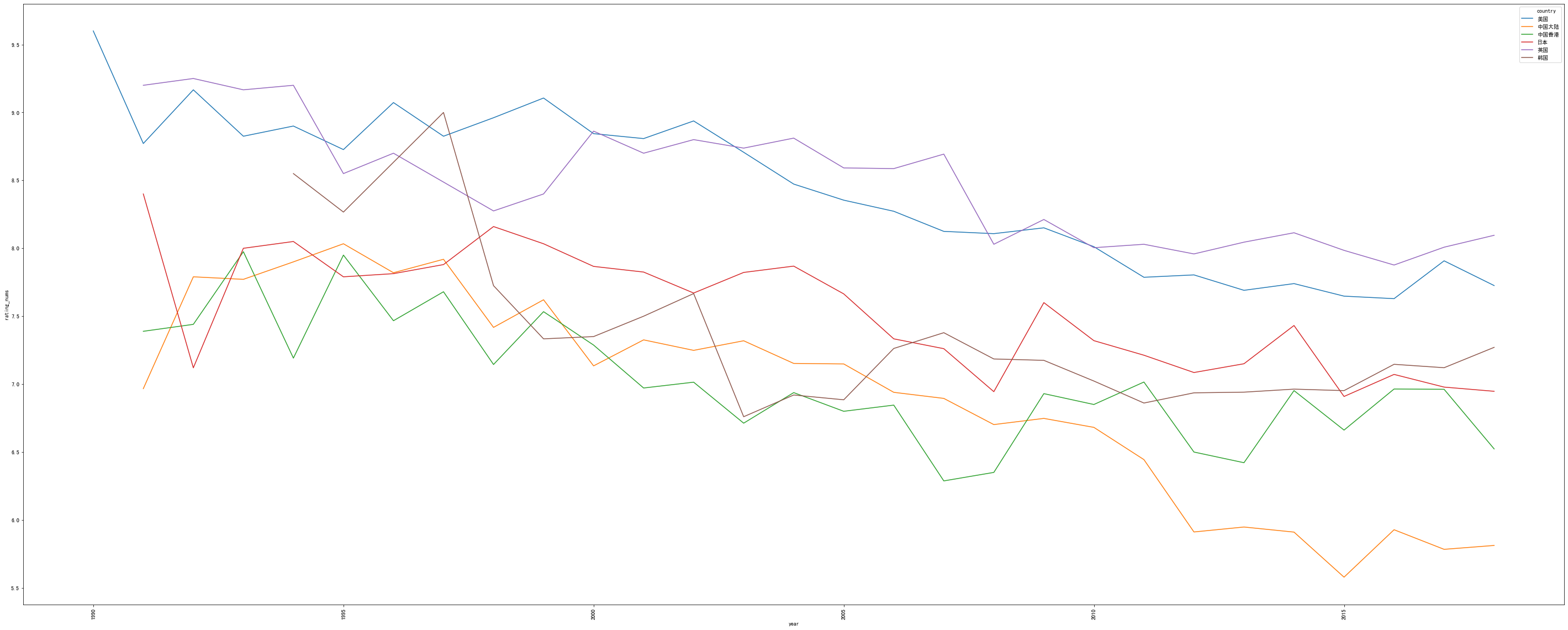
def ten_year_type_count(dften):
s1= ','.join(dften.tv_type)
all_type = re.sub(r',+',',',s1)
return [foo for foo in sorted(Counter(all_type.split(',')).items(),key=lambda item:item[1],reverse=True) if foo[1]>5]
five_list = [ten_year_type_count(df_final[df_final.country=="中国大陆"][df_final.year<=foo][df_final.year>foo-4]) for foo in range(1994,2021,4)]
type_list =list(set([foo1[0] for foo in five_list for foo1 in foo]))
df_five_type = pd.DataFrame(index = [1994,1998,2002,2006,2010,2014,2018],columns=type_list,data=0)
for index,five in enumerate(five_list):
for foo in five:
df_five_type.loc[1994+index*4,foo[0]] = foo[1]
df_five_type<div>
<style scoped>
.dataframe tbody tr th:only-of-type {
vertical-align: middle;
}
.dataframe tbody tr th {
vertical-align: top;
}
.dataframe thead th {
text-align: right;
}
</style>
<table border="1" class="dataframe">
<thead>
<tr style="text-align: right;">
<th></th>
<th>古装</th>
<th>儿童</th>
<th>传记</th>
<th>家庭</th>
<th>历史</th>
<th>动作</th>
<th>惊悚</th>
<th>剧情</th>
<th>战争</th>
<th>悬疑</th>
<th>爱情</th>
<th>奇幻</th>
<th>科幻</th>
<th>喜剧</th>
<th>犯罪</th>
<th>武侠</th>
</tr>
</thead>
<tbody>
<tr>
<th>1994</th>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>13</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>7</td>
<td>0</td>
<td>0</td>
</tr>
<tr>
<th>1998</th>
<td>0</td>
<td>0</td>
<td>0</td>
<td>0</td>
<td>7</td>
<td>0</td>
<td>0</td>
<td>39</td>
<td>0</td>
<td>0</td>
<td>12</td>
<td>0</td>
<td>0</td>
<td>7</td>
<td>0</td>
<td>0</td>
</tr>
<tr>
<th>2002</th>
<td>26</td>
<td>0</td>
<td>0</td>
<td>7</td>
<td>16</td>
<td>0</td>
<td>0</td>
<td>81</td>
<td>0</td>
<td>0</td>
<td>17</td>
<td>0</td>
<td>0</td>
<td>10</td>
<td>10</td>
<td>9</td>
</tr>
<tr>
<th>2006</th>
<td>30</td>
<td>0</td>
<td>0</td>
<td>13</td>
<td>9</td>
<td>8</td>
<td>0</td>
<td>105</td>
<td>9</td>
<td>6</td>
<td>30</td>
<td>0</td>
<td>0</td>
<td>25</td>
<td>6</td>
<td>0</td>
</tr>
<tr>
<th>2010</th>
<td>12</td>
<td>7</td>
<td>0</td>
<td>34</td>
<td>11</td>
<td>12</td>
<td>0</td>
<td>164</td>
<td>20</td>
<td>13</td>
<td>40</td>
<td>6</td>
<td>0</td>
<td>21</td>
<td>9</td>
<td>0</td>
</tr>
<tr>
<th>2014</th>
<td>48</td>
<td>6</td>
<td>16</td>
<td>108</td>
<td>44</td>
<td>19</td>
<td>0</td>
<td>384</td>
<td>82</td>
<td>26</td>
<td>181</td>
<td>11</td>
<td>6</td>
<td>85</td>
<td>13</td>
<td>9</td>
</tr>
<tr>
<th>2018</th>
<td>74</td>
<td>7</td>
<td>0</td>
<td>58</td>
<td>11</td>
<td>20</td>
<td>8</td>
<td>440</td>
<td>52</td>
<td>66</td>
<td>182</td>
<td>50</td>
<td>9</td>
<td>78</td>
<td>30</td>
<td>11</td>
</tr>
</tbody>
</table>
</div>plt.figure(figsize=(20,10))
sns.heatmap(data=df_five_type, annot=True, fmt="d", linewidths=.5)<matplotlib.axes._subplots.AxesSubplot at 0x1a2ffe5be0>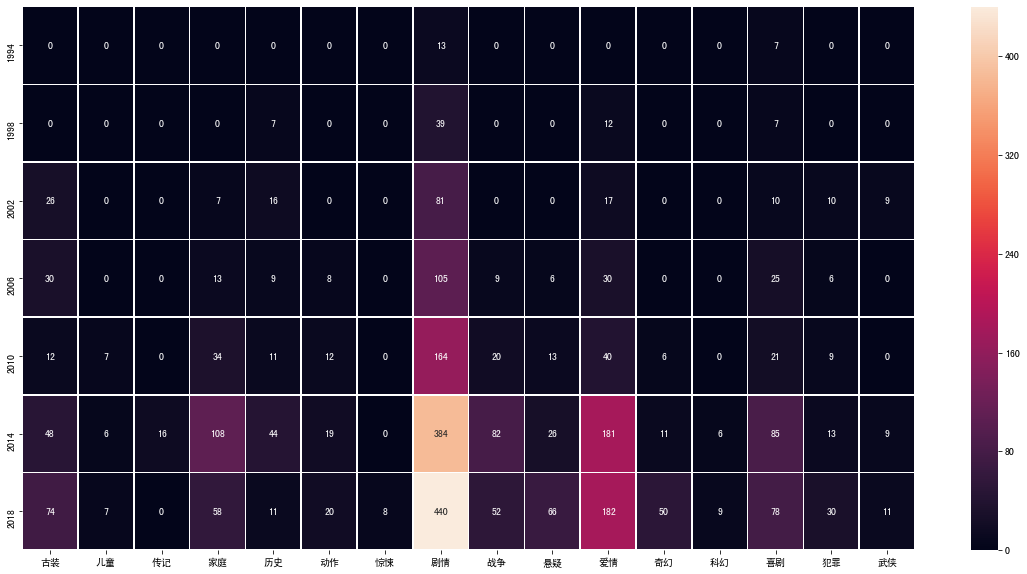
总结
大概地总结一下吧,这里一定程度上真实地反映了人们观念的变化对电视剧市场造成的自然选择以及历史的必然趋势。
之所以说是历史的趋势,可以看到,随着时间的增长,剧种、剧目数量,都呈现上升的趋势,这是由于经济基础的建设,人民满足了基本的物质需求,继而开始追求精神需求的体现。
10 年以前,战争剧稀少,诸如《亮剑》、《团长》等优质的抗战剧大多诞生于这个时期。10 年以后,由于政策的扶持和被优质片打开的市场,战争题材的电视剧开始出现井喷,说好听点良莠不齐,说难听点,一堆杂草群魔乱舞,诸多的“神剧”就是这之后的产物。
家庭、爱情剧方面,这一部分我看的较少,不过大概也是可以分析一下。14 年以前,受韩剧市场大成功的影响,加上题材容易量产,所以得到了资本的大量倾注,诸如《回家的诱惑》等剧就是这个时间段的产物。而 14 年以后,市场由“家庭”偏向“爱情”,主要是因为市场的主力军变了,新生代的大学生开始成为左右这一部分市场的中坚力量,自然市场就要向着迎合这一部分人群的方向发展。
古装剧涨势良好,以往(14 年以前)的古装剧,多以正剧、武侠剧为主(但是因为武侠又以香港地区为主,所以该表显示的武侠剧并没有大家印象中的那么多),而 14 年以后,以于正为首的抄袭派作家找到了量产古装剧的套路,同时,古装剧在“造星”方面有着天然的优势,所以古装剧在近几年发展迅速,尤以“古装+爱情”这样的组合见多。
好吧,暂时就先分析这么多吧,更多的就留着以后有闲工夫了,再做探究。
后记
- 为了这一章特地看了一点 lua
- 相见时难别亦难
再次踏上故乡的土地,这一年里经历良多,以至有物是人非之感。
这一年,辗转各地参加比赛,看到了很多优秀的作品,认识到很多优秀的人,我开始逐渐明白,以前老顾常说的,“这只是一个小地方”,没错,投诸广袤的华夏大地,这片土地只是十分渺小的、不起眼的一点,而我,从小到大所以受到的良多赞誉,也只限于这一点罢了,出了这一点,方知过往的种种妄语,实在是井底之言。
又想起了初中时读《博弈论》,“凡有所失必有所得”,少时懵懂,不解其意,及至今日,这句话却又忽的涌上心头,我失去了什么?又得到了什么?果然,有些事物,越是成长,越是深刻。
所有的念头起于刹那又终于刹那,周身是人潮涌动,他们都去往同一个方向,归乡的人们,大多脸上洋溢着希望与喜悦。
我提起行囊,汇入人海,这一刻,我是沧海的一粟,也是历史的洪流。我是构成这个庞大的名为国家的机器的一个小小的齿轮,也许被替代,但是却无法被复制。
带着这样的觉悟,我向前走去。
– 2020 年 01 月 13 日,写于夜深人静之时。

