
本篇旨在介绍 大模型技术 在 日常工作(主要是开发) 中的使用.
引言
在这个月初参加的 ai-dlc 中, 有提到一个有趣的 vibe coding 工作效率提升的调查统计, 结论是 对于用户而言感觉是提高了工作效率, 但是从客观的评估来看工作效率是降低了的.
在过去的一年里, 基于 cursor , 我维护了 DMS , 海姆达尔, 股东工具 三个主线工作项目, 以及一系列的 依赖 / 工具 与零散需求. 这三个项目各自有鲜明的特征.
- DMS 的项目体量比较大, 至少相对于当前的 context window 来说很大, 业务逻辑盘根错节.
- 海姆达尔则是一个接近黑盒的项目, 它没有文档和单元测试, 可能对于一个 if 的修改, 会影响到一百行以外的一点逻辑 .
- 股东工具的 60% 代码由 ai 实现.
毫无疑问它在工作中确确实实地产生了很大的帮助. 那么为什么会有这样的偏差, 笔者认为是对于 ai 工具的使用策略的问题导致, 工欲善其事, 必先利其器 , 所以也就有了这一篇鸽了很久的分享.
Part1: Vibe Coding 基础
对于我们用户来说, 大模型的最终效果是三个层面的投射. 即 模型(服务层) , 提示词(用户层) , 应用服务(工具层) . 这里我们重点介绍的是主观能动性较强的 用户层 的能力, 次要介绍 服务层 的能力, 工具层则选择 Cursor 进行集中讲解.
Prompt(提示词)
笔者认为提示词算是使用 AI 的入门技能了, 所以这里只进行一些简单的介绍.
为什么我们需要 Prompt Engineering (提示词工程)?
大语言模型(LLM)虽然拥有庞大的知识库, 但它们底层更像是一个概率预测引擎, 而不是一个能直接洞察人类意图的”读心者”. 这意味着, 当你问出 “请为我提取这个网站的内容” 时, 它虽然每次回答倾向一致, 但具体的输出格式和深度会收敛. 此时我们就需要通过 Prompt Engineering 来引导大模型的 Attention(注意力机制), 使其聚焦于我们关注的上下文.
除此之外, 提示词工程还用于解决如下的问题:
- 消除歧义 (Ambiguity Resolution). (如 “Apple” -> 水果还是科技公司?)
- 激发推理能力 (Reasoning). (通过 Chain of Thought (CoT) 引导大模型进行分步思考, 处理复杂逻辑)
- 规范输出 (Output Formatting). (强制要求 JSON 或特定的代码风格)
- 减少幻觉 (Hallucination Reduction). (通过提供 Grounding Data 强调信息的可信度)
明确具体意图
如果你已经知道修复的目标, 则尽量圈定一个问题排查的范围.
wrong: “修复这个函数”
right: “修复这个登录函数的错误处理, 添加对无效密码和网络错误的处理”
指定技术栈
example:
“技术栈: FastAPI; Pydantic v2; aiomysql; SQLModel, which base on SQLAlchemy 2.0 and Pydantic V2”
包含质量要求
example:
“生成代码时包含错误处理、类型检查和单元测试”
提供上下文
IDE 中能够直接通过引用 @ 提供上下文, 而在 dify 这样的平台中, 也能够通过知识库应用的方式引入上下文.
提供上下文的目的在于让 LLM 更好地理解业务背景. 比如, 我如果直接提供网站HTML, 让他解析内容, 相比将该业务的数据表设计一并提供给大模型解析, 肯定是后者的效果更好.
example:
根据 @BaseModel.py 中的 BaseModel 作为基类, 创建一个用户模型.
案例:
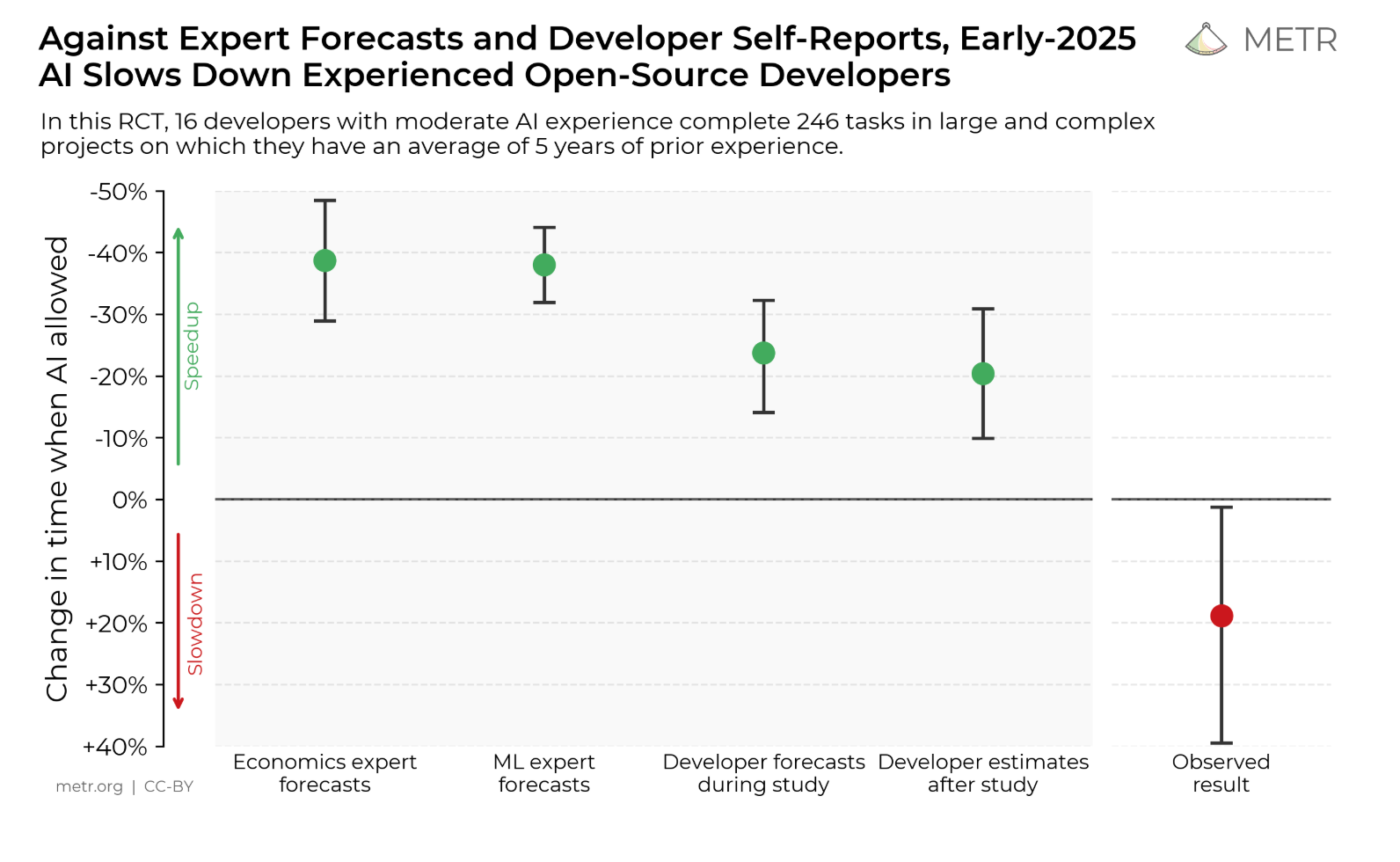
非知识库请求:
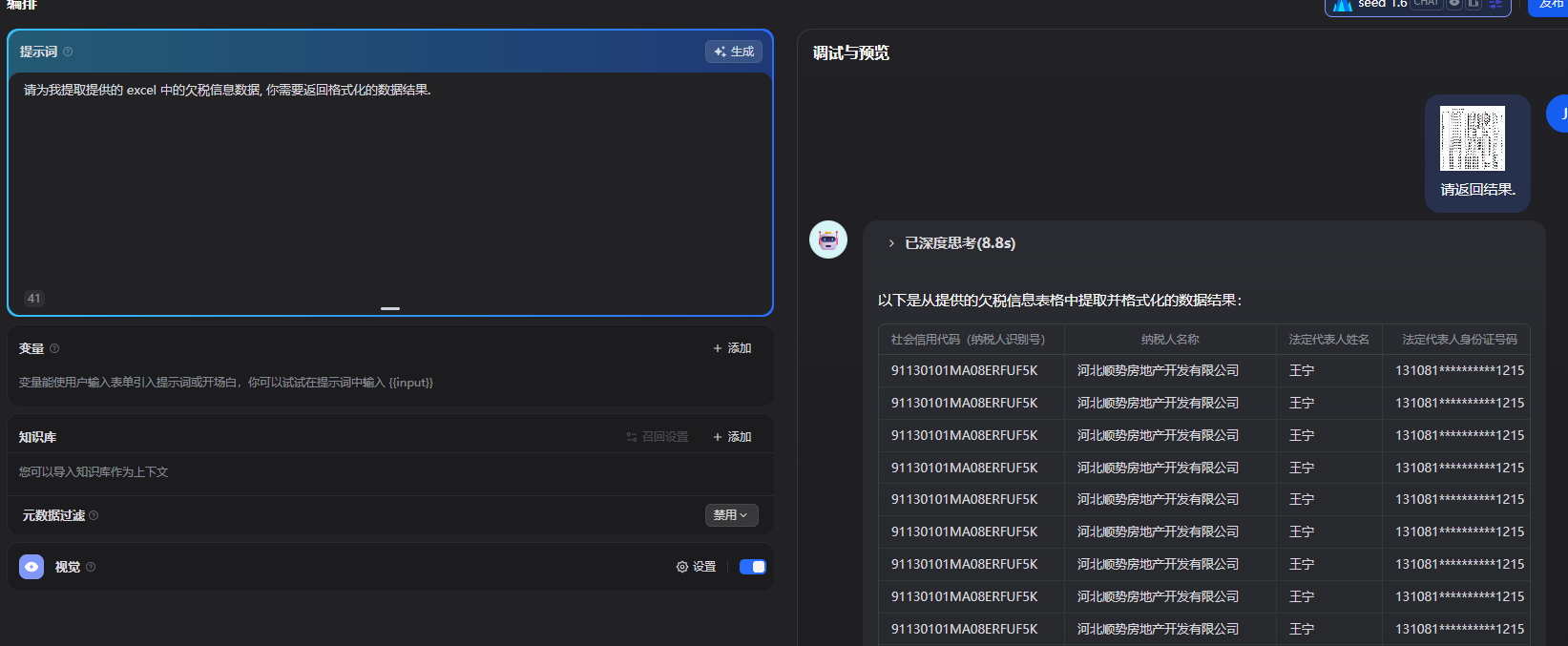
携带知识库请求:
如何获得更好的 AI 输出
提升 AI 输出质量的最佳方式, 就是明确告诉它你希望参考哪些代码.
如果你知道它需要用到某个函数, 或者要实现一个和现有代码类似的功能, 直接把相关文件或片段告诉它.
你不需要精确到具体函数名——毕竟我们用 AI 是为了省事, 不是让自己更累. 只要把类似的实现、相关的文件(比如 @schedule.ts、@utils.ts、@ScheduleHeader.tsx 等)都列出来, 哪怕只是”这里有类似做法”, 都能极大提升 AI 的表现.
AI 虽然见过很多代码, 但你项目的特殊之处, 只有你能补充给它.
扩展: prompt to prompt
在 Prompt 兴起的阶段, 出现了很多奇技淫巧, 比如最广泛使用的 扮演法, 通过假设特定的角色工种在获取在特定领域的优化效果. 但是由于我们需要处理的问题复杂多样, 不同的问题会迭代出不同的 prompt, 所以对于 prompt 的选择与管理成为了新的问题.
于是就有了二阶 prompt. 通过制定一个 “Prompt专家” 来 生成 \ 优化 上述产出的诸多 prompt. 事实证明这个方案会有不错的产出, 并且已经衍生出了一些可堪一用的产品. 这个后文会进行详细介绍.
Model
模型决定了 vibe coding 的能力上限, 是整个 vibe coding 的 CPU .
关于模型
笔者一般从如下的几点来评估一个模型.
- 模型性能
- 模型性能是最核心的评估因素, 它决定了一个模型的上限.
- 上下文窗口 (context window)
- 上下文窗口是指 AI 模型一次性能”记住”和”处理”的信息总量.
- 如果上下文窗口太小, 那么模型很可能会”遗忘”你十分钟前定义的函数,或者因为看不到完整的文件结构而引入冲突的代码(幻觉)。
- 风格
- 各家的模型都拥有鲜明的初始风格. 比如 chatgpt 比较啰嗦, 会将概念都解释清楚; 而 claude sonnet 则更加地干练, 会直接通过代码来解释问题.
- 模型的风格可以通过 prompt 来进行替换, 所以这并不是一个主要的评判标准.
费用
用对的模型
在使用模型之前, 你需要知道这个模型的长处.
以笔者常用的模型举例.
- kimi : 中文场景下的检索, 翻译. 日常使用最多的模型.
- gemini: 全能王, vibe coding 中使用最多的模型. 在价格与性能之间有很好的权衡, 大规模生成代码的场景优先考虑.
- chatgpt: 新技术的引导式学习
- claude: 代码专精, 价格偏贵. 在解决疑难杂症或者进行关键代码生成时会使用.
选择新的模型
不要期望 ChatGPT 3.5 的免费版能完成Claude 3.5 Sonnet级别的复杂任务
付费 > 免费
根据这几年的使用经验, LLM 在推广阶段的免费使用是没有什么问题的, 但是在进入到商业化阶段后, 免费模型的能力会出现较为明显的降智(这里不考虑第三方的情况), 所以网上经常会有这样的声音, “我也是用的 xxx, 为什么效果这么差” .
对于生产力工具, 不必吝啬于付费.
小结
核心: 沟通范式
let @Agent with #Context do sth

