
Transaction Processing or Analytics?
transaction : 在早期的商业数据处理中, 数据库的写入通常与一次商业交易(commercial transaction)有关, 所以即使后期数据库适用范围扩展到其他的领域, transaction 这个术语仍然被沿用下来, 表示一次逻辑上的读写操作.
TP(Transaction Processing) 的意思是允许客户端进行低延迟的读写. 它不一定是具有 ACID (atomicity, consistency, isolation, and durability) 特性的.
- Five types of data processing
- Transaction Processing
- Distributed Processing
- Real-time Processing
- Batch Processing
- Multiprocessing
无论数据库扩展到那个领域, 基本的访问模式仍然类似于处理商业事务. 通过给定的 key 来查找少量的记录, 通过用户输入的数据来进行增改. 由于这些延伸的应用都是交互的, 所以这种访问模式被称为在线事务处理 (OLTP, online transaction processing).
但是数据库同样被广泛地用于数据分析(data analytics), 它拥有与上文不同的访问模式. 数据分析用到的查询, 会扫描大量的记录, 然后读取其中一部分的字段, 进行计算分析, 最后返回分析的结果, 而非 OLTP 返回原始的数据项.
这些查询分析的结果服务于商业公司, 用以做出更好的商业决策. 所以区别于 OLTP, 这种模式被称为 在线分析处理 (OLAP, online analytic processing).
| 属性 | 事务处理 OLTP | 分析系统 OLAP |
|---|---|---|
| 主要读取模式 | 查询少量记录, 按键读取 | 在大批量记录上聚合 |
| 主要写入模式 | 随机访问, 写入要求低延时 | 批量导入(ETL), 事件流 |
| 主要用户 | 终端用户, 通过Web应用 | 内部数据分析师, 决策支持 |
| 处理的数据 | 数据的最新状态(当前时间点) | 随时间推移的历史事件 |
| 数据集尺寸 | GB ~ TB | TB ~ PB |
最初这两种处理方式是使用的同一个数据库, 随着时间的推移, OLAP 开始使用单独的数据库, 也就是 数据仓库 (data warehouse).
Data Warehousing
OLTP 往往是面向商业活动的, 所以通常会要求这些系统实现高可用和低延迟. 因此, DBA 不会愿意让数据分析人员在这些数据库上执行高性能消耗的查询任务.
数据仓库是一个独立的数据库, 分析师可以在上面进行查询而不用担心影响到 OLTP 操作. 数据仓库会从复数个 OLTP 数据库中提取只读的副本(可以是定期的数据转储, 或者是连续的流式更新), 将这些数据转换成适合分析师使用的模式, 清洗, 然后入库. 这个装在数据的过程被称为 Extract–Transform–Load (ETL).
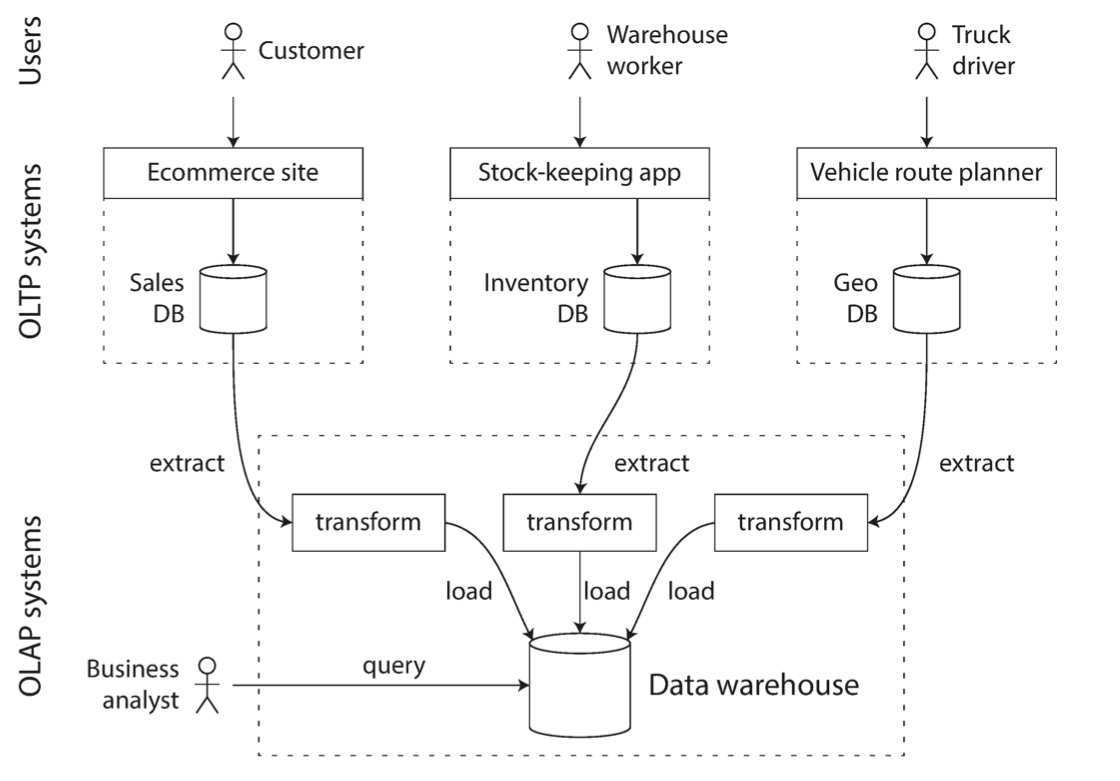
数据仓库的另一个优势是, 比起直接访问 OLTP 数据库, 它能够被优化以更适合数据分析的访问模式. 前文中所提到的 OLTP 的种种索引算法并不能很好地解决数据分析的查询.
The divergence between OLTP databases and data warehouses
数据仓库的数据模型通常是关系型的, 因为 SQL 通常很适合分析查询. 有许多图形数据分析工具可以生成SQL查询, 可视化结果, 并允许分析人员探索数据(通过下钻, 切片和切块等操作).
表面上, 一个 数据仓库 和一个 OLTP 数据库看起来很相似, 因为它们都有一个 SQL 查询接口. 然而, 系统的内部看起来可能完全不同, 因为它们 针对非常不同的查询模式进行了优化. 现在许多数据库供应商都将重点放在支持事务处理或分析工作负载上, 而不是两者都支持.
Stars and Snowflakes: Schemas for Analytics
数据库的数据模型会根据不同的应用领域而产生多种的数据模型, 但是数据仓库的数据模型的多样性要远低于数据库, 许多数据仓库都以相当公式化的方式使用, 被称为 星型模式 (star schema, aka dimen‐sional modeling).
这个模型的中心是一张事件表(fact_table), 表的每一行都是一个事件. 通常情况下, 每一个独立的时间都被视为一条事实(fact), 这样在以后的分析中能够更加灵活地使用这些数据. 但是这也意味着存储的数据会非常之大. 表的列由两部分组成: 其一是事件的属性; 其二是外键, 指向其他的表, 这些子表被称为维度表(dimension tables). 由于事实表中的每一行都表示一个事件, 因此这些维度代表事件发生的 who, what, where, when, how, and why .
这个模板的变体被称为雪花模式(snowflake schema), 它进一步分解了子维度(subdimensions), 然后用更多的外键形成关联. 雪花模式比星型模式更加地规范化, 但是星型模式通常更受青睐, 因为它更易于分析.
Column-Oriented Storage
如前文所说, 事实表将事件事无巨细地进行存储, 所以它的数据量非常地庞大, 如何进行高效地查询就成了一个问题.
在大多数 OLTP 数据库中, 存储都是以面向行的方式进行布局的: 表格的一行中的所有值都相邻存储. 文档数据库也是相似的: 整个文档通常存储为一个连续的字节序列. 文档型数据库也是类似的, 一个完整的文档它存储在一个连续的空间上.
即使我们已经提前规定了索引, 但是行存储仍然需要将所有这些行(对于大数据, 可能一行会有超过100个属性)从硬盘加载到内存中, 解析然后过滤掉不符合要求的属性.
Let’s assume a Disk can only hold enough bytes of data for three columns to be stored on each disk.
To get the sum of all the people’s ages the computer would need to look through all three disks and across all three columns in each disk in order to make this query.
So we can see that while adding data to a row oriented database is quick and easy, getting data out of it can require extra memory to be used and multiple disks to be accessed.
列式存储背后的想法很简单: 不要将所有来自一行的值存储在一起, 而是将来自每一列的所有值存储在一起. 如果每个列式存储在一个单独的文件中, 查询只需要读取和解析查询中使用的那些列, 这可以节省大量的工作.
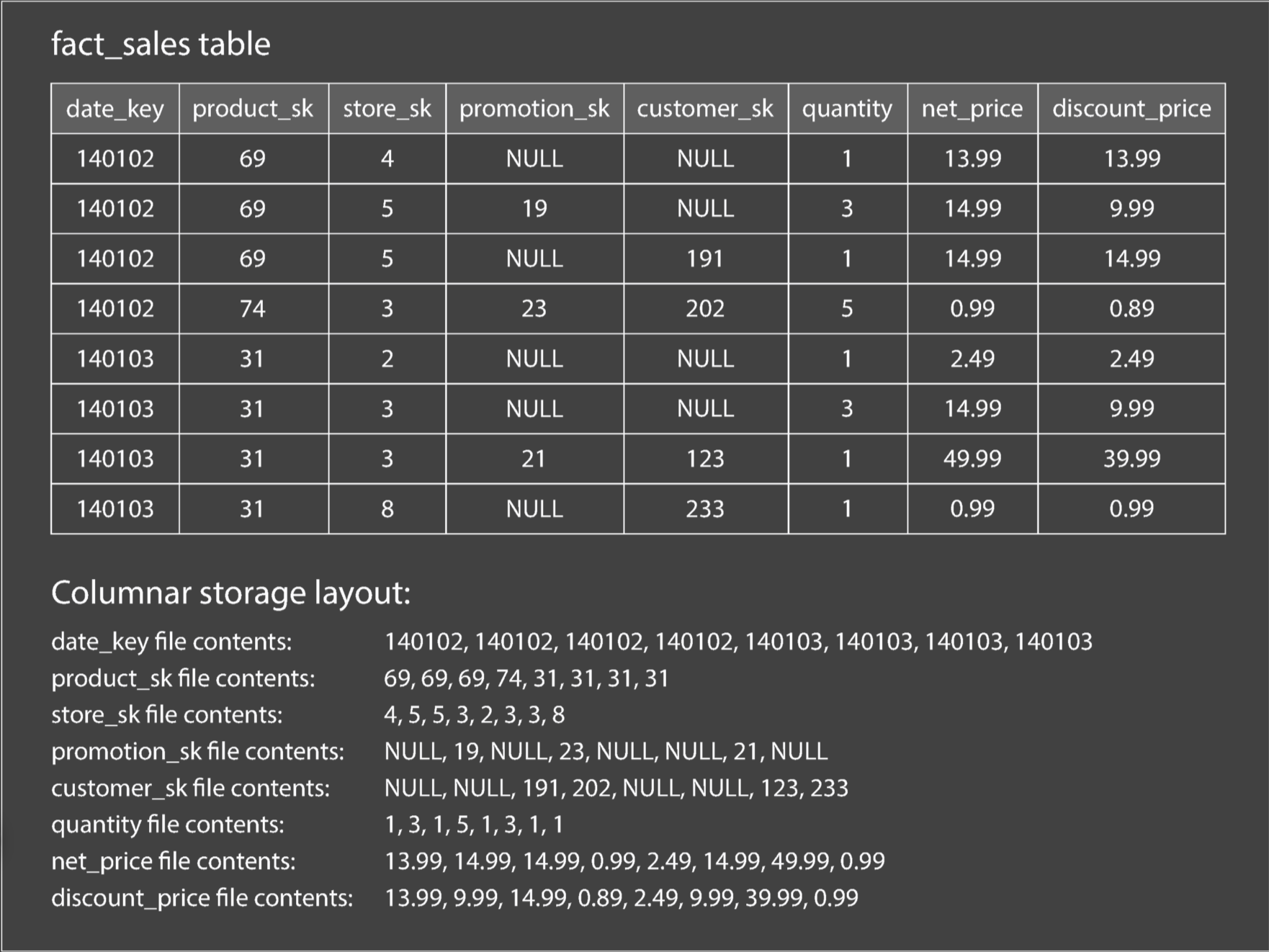
Column Compression
列压缩的一个主要原因是列式存储的数据在特征上通常是稀疏的, 通常情况下, 一列中不同值的数量与行数相比要小得多. 在数据仓库中特别有效的一种技术是 位图编码(bitmap encoding) .
Memory bandwidth and vectorized processing
对于需要扫描数百万行的数据仓库查询来说, 一个巨大的瓶颈是 从硬盘获取数据到内存的带宽 . 但是, 这不是唯一的瓶颈. 分析型数据库的开发人员还需要有效地 利用内存到 CPU 缓存的带宽 , 避免 CPU 指令处理流水线中的分支预测错误和闲置等待, 以及 在现代 CPU 上使用单指令多数据(SIMD, single-instruction-multi-dat)指令来加速运算 .
列压缩允许列中的更多行被同时放进容量有限的 L1 缓存. 前面描述的按位 “与” 和 “或” 运算符可以被设计为直接在这样的压缩列数据块上操作. 这种技术被称为 矢量化处理(vectorized processing) .
Sort Order in Column Storage
在列存储中, 存储的顺序并不重要, 但是, 我们也可以选择按某种顺序来排列数据, 就像我们之前对 SSTables 所做的那样, 并将其用作索引机制.
数据的排序需要对一整行统一操作, 即使它们的存储方式是按列的. DBA 通常会根据数据的特征来进行分级排序, 每一级的索引都对应一列, 显然第一列的排序效果会是最好的.
按顺序排序的另一个好处是它可以帮助压缩列. 排序将相同的值聚集在一起, 通过位图压缩的思路能够将某一行压缩到很小, 但是这种压缩效果会随着排序优先级的增长而大幅降低.
Several different sort orders
在一个列式存储中有多个排序顺序有点类似于在一个面向行的存储中有多个次级索引. 但最大的区别在于面向行的存储将每一行保存在一个地方 (在堆文件或聚集索引中) , 次级索引只包含指向匹配行的指针. 在列式存储中, 通常在其他地方没有任何指向数据的指针, 只有包含值的列.
Writing to Column-Oriented Storage
前文所述的 压缩 / 排序 都是方便了查询, 但是却会加大写入时的成本. 通过 LSM 树, 所有的写操作首先进入一个内存中的存储, 在这里它们被添加到一个已排序的结构中, 并准备写入硬盘. 内存中的存储是面向行还是列的并不重要. 当已经积累了足够的写入数据时, 它们将与硬盘上的列文件合并, 并批量写入新文件.

