前言
惯例的前言,这次这个小玩具又是一个来源于生活的东西了。
上次写了一个基于 linux 的自动打卡机,但是最近又有了新的需求。。。
其一是学校的每一次表单变更都需要进入项目进行代码级别的修改、测试、部署,实在是太过麻烦。
其二是以往的自动化需求太高,而对于没有服务器的同学只能看着眼馋。
于是这次写了一个基于 flask 的自动打卡网站,emmm,暂时没啥 bug。
正文
构建思路
本来是想要用传统的 Flask+MySQL 结构的,不过想想要写一大堆的数据库构建语句,好麻烦啊。。。。于是掏出了寒假学的 redis,嗯,不用设计数据库真香。
那么这个项目有哪些核心问题呢?
- 使用了 redis 之后,省略了 models 一步,但并不意味着数据库就啥都不用考虑了。应该选择哪种数据格式?键值如何对应?这些都是问题。
- 定时任务。总不可能真的就 time.sleep(24*60*60-10)来安排吧~
解决问题
如何实现定时
在 Linux 中,我们使用 cronlab 来实现时间调度,但是查阅资料之后,Flask 也有一个很有趣的时间调度框架——APScheduler。
在一年之前更新的版本之中,APScheduler 引入了装饰器写法。以下给出一个小例子。
@scheduler.task(trigger='cron', id='test_job', hour='*')
def test_job():
print('harumonia')数据格式
键值对如何设计呢?首要考虑的一个因素就是索引方便。
既然提到了索引,那么最佳备选跃然纸上——哈希。
需要提一下的就是,这里并不是指作者索引,而是程序索引。如何使程序用较少的执行步骤完成作业内容呢?定时任务,自然是以时间为主轴,于是初步选定以时间为 key。然后 field 如何选择?这里剩下两个选择方向 curl 和执行者索引,执行者索引明显效率更高,索引结果更清楚,于是 input 这一块的数据结构就敲定了。
最后是 output 这一块的数据结构。这个打卡机不能是一个“黑洞”,有输入必然要有输出,这里的输出就是执行的结果。每次打卡完成之后,根据返回的 json,来判断打卡是否完成,如果没有完成,那么需要显示出来,毕竟我们做的是一个便民的工具,而不是一个害人的工具:D
出于方便聚合的考虑,输出这里依然使用哈希结构。同时,根据 value 中的 name 来实现 key-value 与 value-key 的嵌套约束,这样可以省去很多的判断和循环。
如何执行
录入的是 curl 命令,笔者一开始的想法是直接使用 python 去执行 shell,但是这样做的一个问题就是,给熟悉的人使用自然没有问题,给坏心思的使用,直接一个注入攻击,把服务器搞瘫痪了咋办?
于是还是保险一点,使用 requests 来完成 post 操作。curl 可以让用户更加方便地输入(仅仅一行,不是不 post 表单要方便多辣),所以就保留了。我们要做的就是从 curl 中提取我们所需要的信息,
这里选择使用正则表达式来进行分析,最终我们可以顺利地提取出 url、headers、data 等关键信息。
如何使用
已经部署好啦 “http://daka.harumonia.top:5008/"
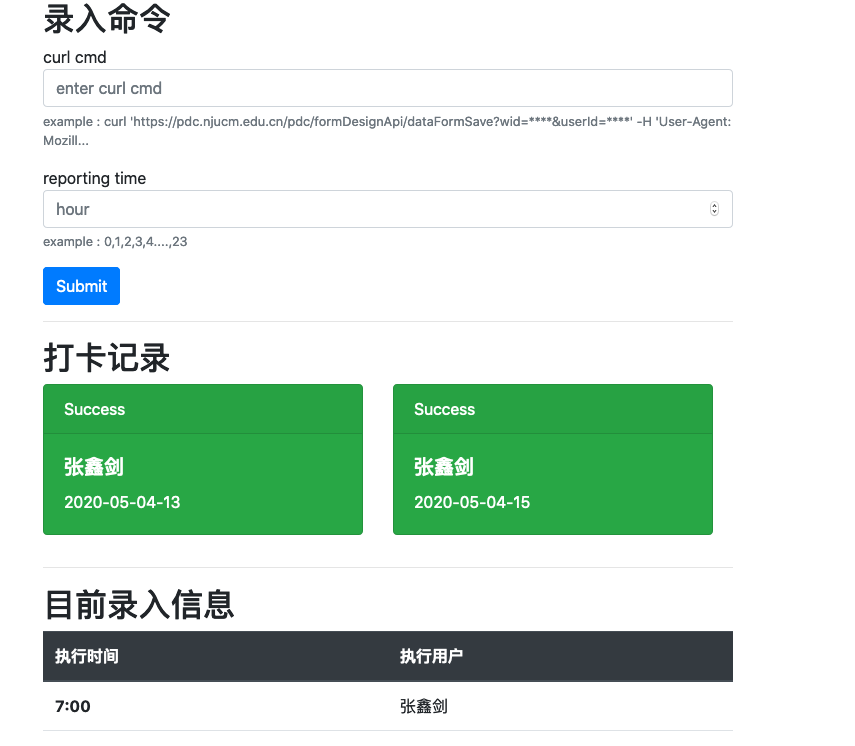
S1 获取 curl 命令
进入浏览器,进入开发者界面,然后进行一次成功的打卡交互.
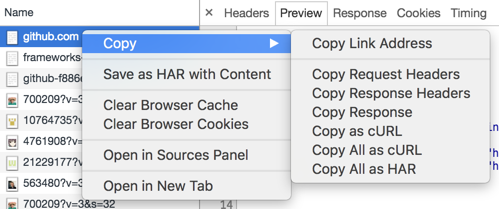
这时可以在开发者界面的”网络(network)”中发现一个 post 交互,进行如下图的操作(Copy as cURL),就可以得到 curl 命令
curl 例子: curl ‘https://pdc.njucm.edu.cn/pdc/formDesignApi/dataFormSave?wid=****&userId=****' -H ‘User-Agent: Mozill…
S2 录入
将得到的 cURL 录入到网页的表单中
第二个选项是选择打卡的时间,if 输入 3,就是每天 3 点进行打卡.
默认一次录入一条,如果一天中需要多次打卡的,多次录入即可
S3 检查
第一次录入之后,在到点时检查一下是否正确执行了,over
更新记录
v1.1
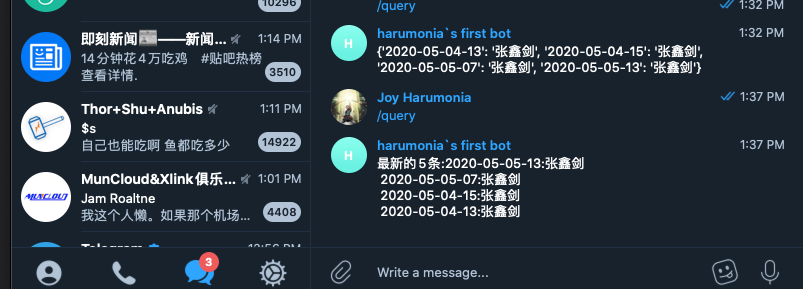
- 使用一个萌萌的机器人来进行事务完成和失败的相关通知
- 修改配置文件的存放思路
最后
这个系统还有很多强化的地方,预计加入一个邮件提示,失败的时候可以及时知道相关的信息。
感觉要感冒了,不想被隔离啊 o(╥﹏╥)o

