感觉已经一万年没有更新博客了。。。这次是制作一个简单的爬虫。
前言
本学期有一门纯文科的课程,名唤“医疗仪器原理”。谓之纯文科,自然是要背诵的题目太多了,多到了梦回高中历史的地步= =。
授课老师喜欢使用雨课堂发布习题,但是雨课堂没有办法导出题目和答案,想要整理就只能一条一条地复制粘贴,更骚的是,这个网站的题目默认被转成了图片格式(???)。好嘛,复制粘贴都做不到了。

这种复习的效率实在是太低了,于是准备重操旧业,开始爬虫工程(面向监狱编程)
开始
S1 抓包分析
在进行交互分析之后,发现了一个有趣的链接,这个链接的文本量大得出奇,而且类型是 json!~一般这样的链接,就是我们交互分析的最终目标了。
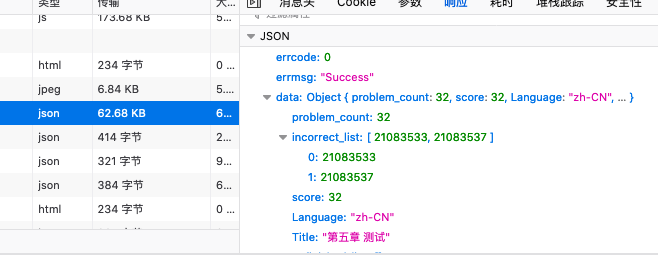
这样一来,数据来源问题就解决了。
继续分析,他所有的题目和答案都是保存为图片,然后给出了一个图片链接。第一次见到这种奇葩的设计,难道是为了防止我这种”数据小偷”吗?
图片可以直接抓下来,但是就这样贴到笔记本上,十分地麻烦,关键是不美观啊。
于是想到了一个解决方案,OCR~
S2 OCR
这里我选择直接使用百度的 OCR api,百度家的识别率不错,而且文档也挺齐全的,这里就不多做赘述了,直接放上文档链接。
不过在识别的过程中倒是出现了一个小插曲。
png 问题
第一次识别之后,明明本地每个文字都很清楚,但是识别结果就是空。由于这是一个黑盒的过程,我也不知道中间到底是出了什么问题。
我能想到的第一个解决思路就是尽量拆解黑盒。于是我又找了一家 OCR,然后就发现过程中出现了这样的情况。
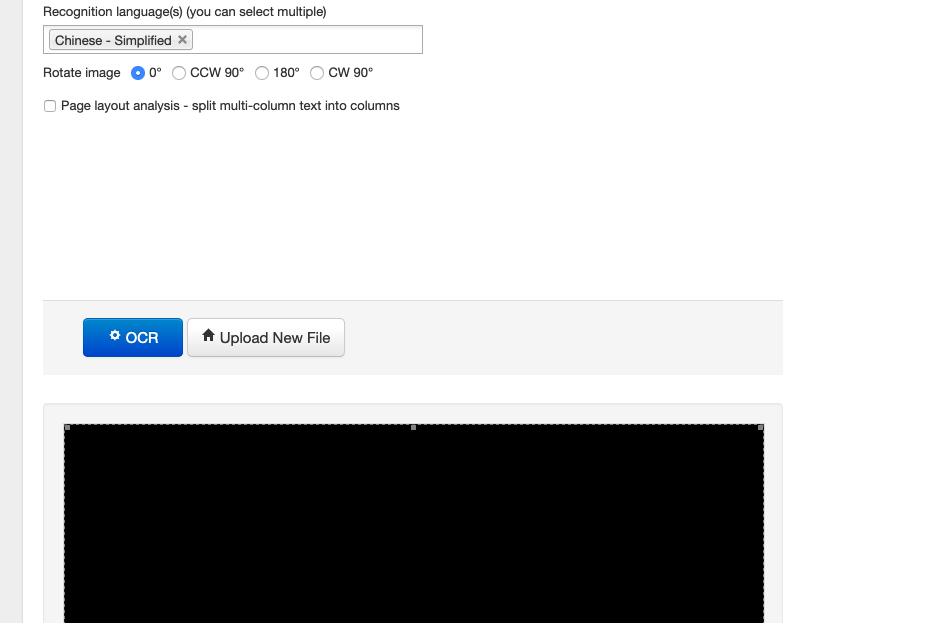
无背景的 png 格式的图片,上传之后背景默认被填充为了黑色,这样就与原本的文字颜色(黑色)冲突了,直接把文字给同化了。
图像预处理
我对于数字图像的本质理解并不是很深刻,无法从编码层面解决问题,不过条条大路通罗马。
我的解决思路就是对图像进行一个预处理,赋予图像一个背景颜色,然后再进行 OCR。这个背景颜色自然是与文字颜色越泾渭分明越好,于是选择了白色。

如此,清晰明了。进行 OCR 之后,顺利识别出了我们需要的内容。
S3 爬虫
S3.1 批量分析
真的是有够别扭的,雨课堂所有的答案也是保存为图片格式的,最令人发指的是,他的选择题竟然是拆分的图片,也就是说,一个 ABCD 四项的选择题,连上题目一共有 5 张图。。。
S3.2 区分题型
回传的数据中,并没有出现类似‘选择’、‘判断’这种能够显示地区分题型的字段。
在分析之后,发现所有的题型可以归总为三大类,选择、填空、解答。
选择题的判断很简单,选择题的答案都是由 ABCD 这样的字母构成,用正则判断是否是全英文答案即可。
小插曲:忘记了多选题,报错。
其实无论是”A”还是”ABC”,在 python 中都是字符数组,不需要区分单选还是多选,直接遍历字符串即可。然后把得到的结果拼接起来就行了。
解答题有一个不知道有啥用的特殊字段,正好我们可以那然作为判断标志。
剩下来的就是填空题咯。
S4 结果
最终爬虫的结果如下(部分)
7 : 尿液分析仪通常由[填空1]填空2]和[填空3]三部分组成
{'1': '机械系统', '2': '光学系统', '3': '电路系统'}
8 : 临床应用最普遍的自动化血培养检测系统主要有利用感受器的[填空1和利用培养基中变化的[填空2两种检测技术。
{'1': '比色法', '2': '荧光测定法'}
9 : 聚合酶链反应技术类似于DNA的天然复制过程,其特异性依赖于靶序列两端互补的寡核苷酸引物,由[填空们、[填空2]、[填空3]三个基本反应步骤构成。
{'1': '变性', '2': '退火', '3': '延伸'}
10 : 血液细胞分析仪的血细胞计数原理是()
电阻抗脉冲法
11 : 使用鞘流技术的设备是()
流式细胞仪
12 : 流式细胞仪的荧光检测使用()
光电倍增管
13 : 全自动血凝仪基本组成不包括
紫外线产生系统识别率尚可~
代码
ans_dic = {'A':1,'B':2,'C':3,'D':4}
url = 'https://www.yuketang.cn/v2/api/web/quiz/quiz_result?classroom_id=*****&quiz_id=****'
headers = {
涉及隐私,战术打码
}
req = requests.get(url,headers=headers)
slides = req.json()['data']['Slides']
def pic_process(pic_path):
im = Image.open(pic_path)
x,y = im.size
p = Image.new('RGBA', im.size, (255,255,255))
p.paste(im, (0, 0, x, y), im)
pic_processed_path = pic_path.replace('pre_process','process')
p.save(pic_processed_path)
return pic_processed_path
def ocr(pic_processed_path):
request_url = "https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic"
f = open(pic_processed_path, 'rb')
img = base64.b64encode(f.read())
params = {"image":img}
access_token = 继续打码
request_url = request_url + "?access_token=" + access_token
headers = {'content-type': 'application/x-www-form-urlencoded'}
response = requests.post(request_url, data=params, headers=headers)
if 'words_result' in list(response.json().keys()):
return ''.join([foo['words'] for foo in response.json()['words_result']])
else:
print(pic_processed_path,'failed.',response.json())
for index in range(len(slides)):
answer = slides[index]['result']
if isinstance(answer,str) and len(re.match('(\D+)',answer).groups()[0]) == len(answer):
fin_answer = []
for foo in answer:
name = re.match('.*?cn/(.*)',slides[index]['Shapes'][ans_dic[foo]]['URL']).group(1)
pic_url = slides[index]['Shapes'][ans_dic[foo]]['URL']
req_pic = requests.get(pic_url)
pic_path = 'yuketang_pic/pre_process/'+name+'.png'
with open(pic_path, 'wb') as file:
file.write(req_pic.content)
pic_process_path = pic_process(pic_path)
answer = ocr(pic_process_path)
fin_answer.append(answer)
answer = ','.join(fin_answer)
if 'is_subject_finish' in slides[index].keys():
answer = slides[index]['Problem']['Remark']
name = re.match('.*?cn/(.*)',slides[index]['Shapes'][0]['URL']).group(1)
pic_url = slides[index]['Shapes'][0]['URL']
req_pic = requests.get(pic_url)
pic_path = 'yuketang_pic/pre_process/'+name+'.png'
with open(pic_path, 'wb') as file:
file.write(req_pic.content)
pic_process_path = pic_process(pic_path)
ques = ocr(pic_process_path)
print(index,": ",ques,'\n',answer)最后
日常表白 tt,晚上早点睡觉哦

